‘ChatGPT’ 개발 및 적용
거대 언어 모델 GPT-3를 미세조정(fine-tuning)한 특정 전문 분야의 챗봇으로 사용자가 질문을 하면 상세하고 정확한 응답을 전달합니다.
ChatGPT란?
-
ChatGPT는 OpenAI가 2022년 11월에 발표한 GPT 구조를 사용한 대화형 인공지능 모델로 2022년 발표된 GPT-3.5를 기반으로 만들어졌습니다.
-
사용자가 제공하는 문장(프롬프트)을 기반으로 텍스트를 생성하여 사용자를 돕는 것이 ChatGPT의 주 기능입니다.
-
GPT는 트랜스포머 모델의 디코더 부분을 가져와 사용하였습니다. 트랜스포머는 셀프 어텐션 기술을 사용하여 문장 내의 단어들 사이의 관계를 이해하고, 이를 기반으로 문장의 맥락과 의미를 학습하는 모델입니다.
-
ChatGPT는 회화형 데이터셋을 사용하여 파인튜닝 되어 대화적 성격의 문맥에 맞춰 자연스러운 텍스트를 생성하기 위해 매개변수가 최적화 되어 있어 챗봇을 만드는 데 적합합니다.
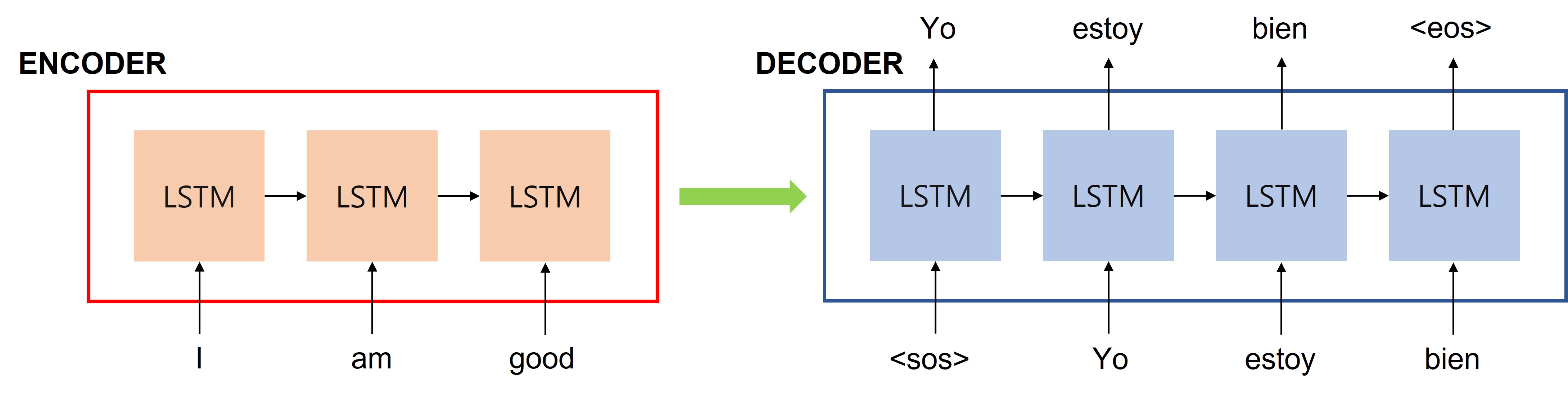
RNN(순환 신경망)과 LSTM
-
RNN(Recurrent Neural Network)은 입력과 출력을 시퀀스 단위로 처리하는 시퀀스 모델로, 매 스텝의 아웃풋이 다음 스텝의 인풋으로 입력되어 이전 스텝의 정보에 접근이 가능합니다.
-
바닐라 RNN은 짧은 시퀀스에서만 효과를 보이고, 스텝이 길어지면 이전의 정보가 뒤로 충분히 전달되지 못하는 Vanishing Gradient라는 단점이 있습니다.
-
LSTM(Long Short-Term Memory)은 불필요한 기억을 지우고 기억해야 할 것들은 정하는 방식으로 Vanishing Gradient의 단점을 보완한 RNN 모델입니다.
Seq2seq (Sequence-to-Sequence)
-
Seq2seq 모델은 인코더-디코더로 구성된 모델로 문장(단어들의 시퀀스)를 입력으로 받아 출력으로 다른 문장을 생성할 수 있습니다.
-
인코더는 입력 문장의 모든 단어들을 순차적으로 입력 받은 뒤 마지막에 모든 단어 정보를 압축하여 마지막 시점에 컨텍스트 벡터라는 하나의 벡터로 만듭니다. 이 컨텍스트 벡터는 디코더로 전송되며, 디코더는 컨텍스트 벡터를 이용하여 새로운 단어를 하나씩 출력합니다.
-
Seq2seq에서 인코더와 디코더는 RNN 모델인 LSTM으로 구성되어 있습니다.
-
디코더는 다음에 올 단어를 예측하고, 그 예측한 단어를 다음 시점의 RNN 셀의 입력으로 넣는 행위를 반복합니다.
-
Seq2seq는 입력 시퀀스가 주어졌을 때 올바른 출력 시퀀스를 출력할 확률성을 높이는 방식으로 훈련됩니다.
Attention
-
어텐션은 시퀀스 요소들 가운데 태스크 수행에 중요한 요소에 집중하는 것입니다.
-
트랜스포머에 사용되는 어텐션은 셀프 어텐션 기법으로, 입력 시퀀스 가운데 태스크 수행에 의미 있는 요소 위주로 정보를 추출할 수 있습니다.
-
기존 seq2seq 모델은 인코더가 입력 시퀀스를 하나의 벡터로 압축하는 과정에서 입력 시퀀스의 정보가 일부 손실되는 문제점이 있었는데, RNN 대신 셀프 어텐션 기법을 사용하여 디코더가 맨 마지막의 컨텍스트 벡터에만 접근하는 대신 모든 입력 단어에 접근할 수 있게 되었습니다.
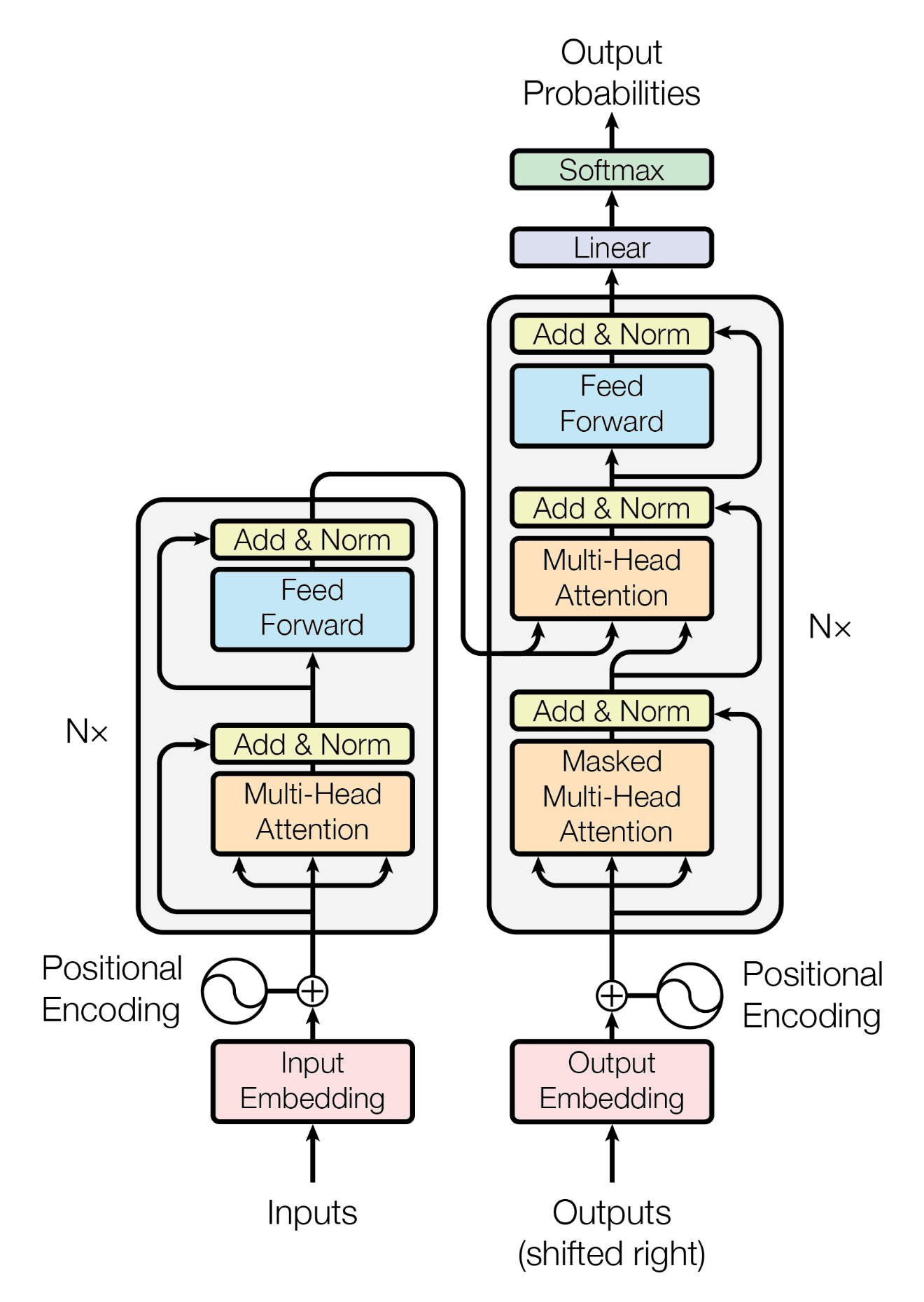
Transformer
-
트랜스포머는 2017년 구글에서 발표한 셀프 어텐션을 사용하는 sequence-to-sequence 모델입니다.
-
트랜스포머는 셀프 어텐션 기술을 사용하여 문장 내의 단어들 사이의 관계를 이해하고, 이를 기반으로 문장의 맥락과 의미를 학습할 수 있는 모델입니다.
-
트랜스포머의 인코더는 소스 시퀀스 간의 관계 정보를 담은 히든 벡터를 출력합니다.
-
트랜스포머의 디코더는 인코더가 보내준 히든 벡터를 받아 매번 인풋 시퀀스의 각기 다른 부분에 집중하며 단어를 출력합니다.
-
트랜스포머는 기계번역과 시계열 예측에 뛰어난 성능을 보이며, GPT와 BERT, chatGPT 같은 다양한 자연어처리 모델들에 사용됩니다.
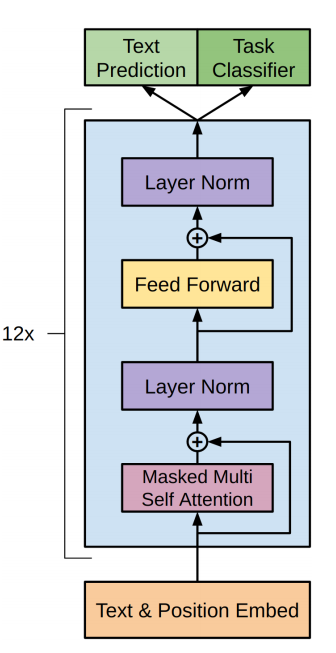
GPT란?
-
GPT는 Generative Pre-trained Transformer의 약자로 대규모의 데이터로 훈련하여 자연어의 표현을 학습한 인공지능 모델입니다.
-
GPT는 파인튜닝을 통하여 번역, 텍스트 요약, 텍스트 생성과 같은 다양한 자연어 처리 태스크를 수행할 수 있습니다.
-
GPT는 트랜스포머의 디코더 부분을 사용하여 이전에 생성된 단어의 문맥에 기반하여 새로운 단어를 매번 생성해냅니다.
-
GPT는 다음에 올 단어를 예측하는 비지도 학습 방식으로 훈련되었습니다.
GPT-3
-
GPT-3는 GPT의 3세대 모델로 2020년 OpenAI에서 발표한 언어 모델입니다.
-
GPT-3는 이전 세대의 모델들과 기본적인 구조는 같지만 더 많은 1750억개의 파라미터와 96개의 디코더 레이어를 갖고 있으며, 더 많은 데이터를 사용하여 훈련되어 이전 세대의 GPT 보다 더 좋은 성능을 보입니다.
-
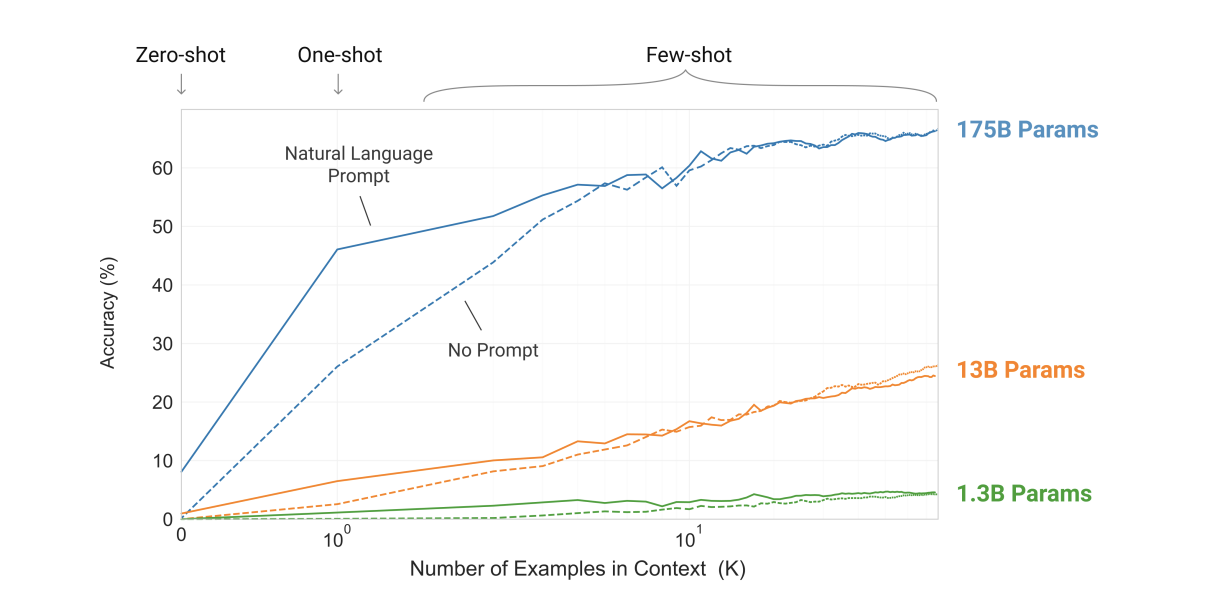
GPT-3는 예시 몇 가지 만으로도 새로운 태크스를 수행하는 퓨 샷 러닝과, 예시가 없이도 다양한 자연어 처리 태스크를 해결할 수 있는 제로 샷 러닝 능력을 갖고 있습니다.
-
GPT-3는 이전 세대의 모델들보다 영어를 제외한 다른 언어들을 다루는 능력이 더 뛰어납니다.
Fine-Tuning GPT
GPT 모델을 fine-tuning(미세조정)하는 방법은 대표적으로 아래와 같습니다.
- Fine-Tuning
- Few-Shot Learning
- One-Shot Learning
- Zero-Shot Learning
- LoRA (Low-Rank Adaptation of Large Language Models)
- P-Tuning
Fine-Tuning (FT)
가장 일반적인 접근법으로, 사전학습된 모델을 원하는 태스크에 맞도록 지도학습 데이터셋으로 학습시키는 과정을 포함합니다. 보통 수천~수만 개의 라벨링된 예시를 필요로 합니다.
장점
단점
-
모든 태스크마다 큰 데이터셋을 새로이 필요로 합니다.
-
분포 외의 데이터에 대해서는 일반화를 잘 하지 못합니다.
-
학습 데이터에 거짓/비논리적인 특성이 있는 경우 이를 흡수할 수도, 사람에 비해 불공정한 비교로 이어질 수도 있습니다.
Few-Shot Learning
데이터셋에서 예시는 문맥과 원하는 답이 있고, few-shot은 단 K개의 문맥과 답이 주어집니다. 이후 마지막으로 단 한 개의 프롬프트가 주어지면, 모델은 정확한 답을 생성해 내야 합니다. 모델의 context window에 넣을 수 있는 만큼 많은 예시(K)를 넣습니다. 일반적으로 가능한 context 길이 2048에 들어가는 10~100개의 예시를 넣습니다.
장점
-
task-specific한 데이터에 대한 필요를 크게 줄여줍니다. 극단적으로는 몇 개 뿐이어도 충분합니다.
-
지나치게 크고 좁은 분포를 갖는 미세조정용 데이터셋을 학습할 가능성을 줄일 수 있습니다.
단점
-
미세조정과 비교하여 성능을 떨어집니다.
-
적은 수라 해도 여전히 task-specific한 데이터를 필요로 합니다.
One-Shot Learning
few-shot과 비슷하나 단 한 개의 예시와, 태스크에 대한 자연어 지시문(instruction)이 제공된다는 점이 다릅니다.
Zero-Shot Learning
예시는 넣지 않고, 수행할 태스크에 대한 설명(description) 혹은 지시문(instruction)만을 넣습니다. 사람이 태스크를 수행하는 것과 가장 가까운 방식입니다. 사람은 텍스트 지시문(예: 'Cheese'라는 영어 단어를 프랑스어로 번역하라)만을 보고도 무엇을 해야 할지 알 수 있기 때문입니다.
장점
-
노이즈나 이상치(outlier) 데이터가 없습니다.
-
거짓 상관관계가 없습니다.
-
따라서 가장 편의성이 높습니다.
단점
-
예시가 없으면 태스크에 대해 제대로 이해하지 못할 수 있다.
In-context learning
-
예시 수 K를 늘릴 수록 성능이 향상됩니다. 즉, 주어지는 예제가 많아질수록 큰 폭으로 성능이 높아집니다.
-
모델이 커질수록 in-context learning의 효율이 높아집니다.
-
태스크에 대한 프롬프트를 함께 넣는 것이 도움이 됩니다.
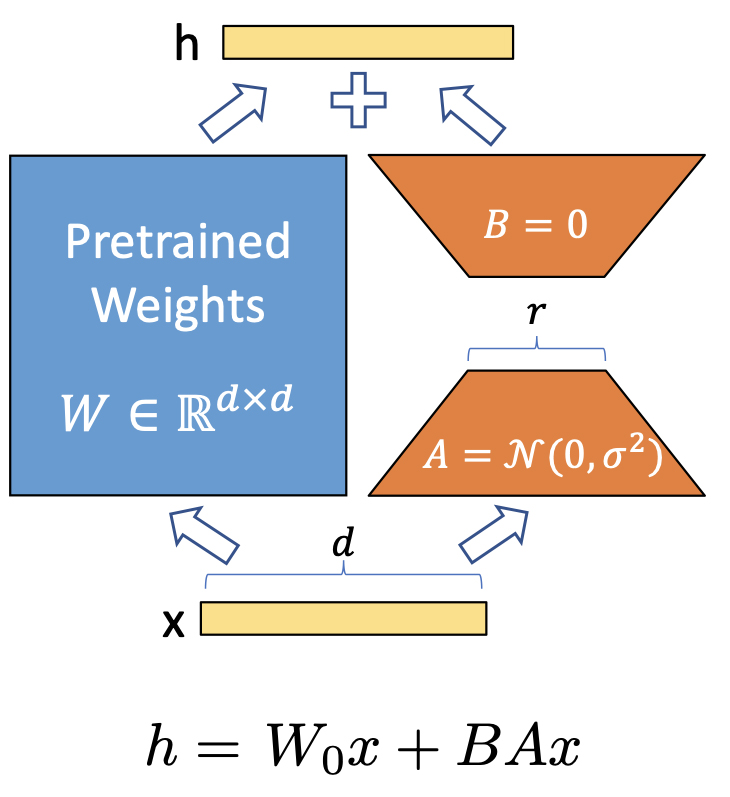
LoRA: Low-Rank Adaptation of Large Language Models
-
GPT-3같은 거대한 모델을 fine-tuning하면 1000억 개가 이상의 파라미터들을 모두 재학습시켜야 합니다. 이는 계산량도 많고 시간도 오래 걸리는 부담스러운 작업입니다. LoRA는 이를 해결할 수 있습니다.
-
원래 파라미터는 동결시키고 트랜스포머 구조의 각 레이어마다 학습가능한 rank decomposition matrix들을 추가하는 방식을 도입하였습니다.
-
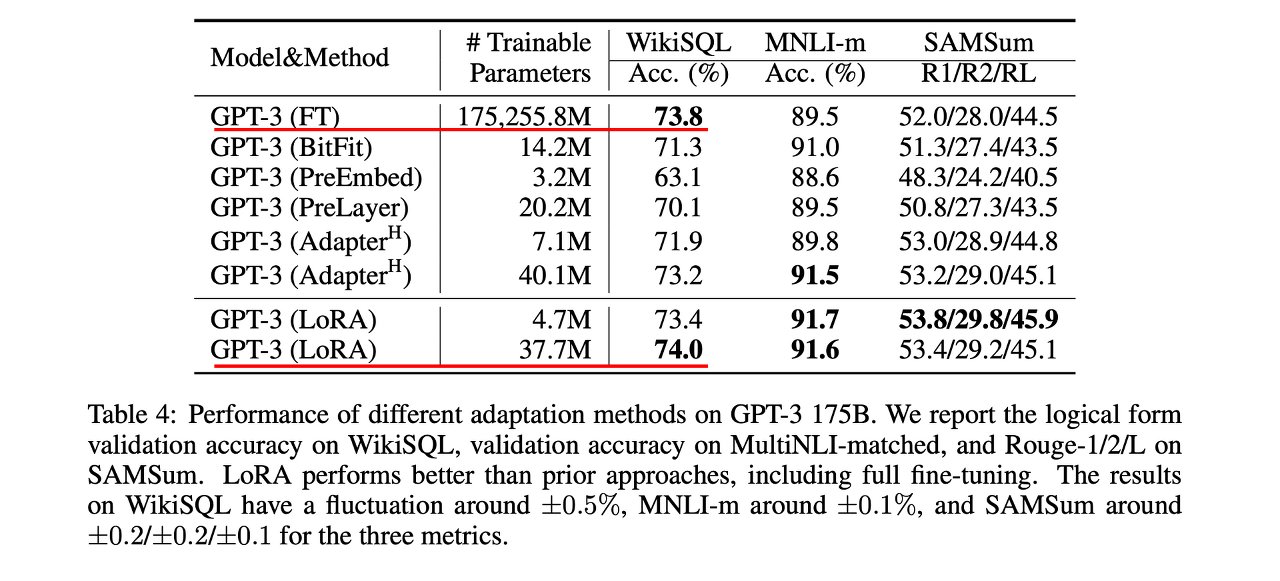
LoRA 방식으로 GPT-3를 fine-tuning하면 메모리는 3배, 파라미터는 10,000배 줄일 수 있습니다. 또한 RoBERTA, DeBERTa, GPT-2, GPT-3같은 모델에서 비슷하거나 더 높은 fine-tuning 성능을 보였습니다.
장점
-
사전학습된 모델을 그대로 공유하면서 작은 LoRA 모듈을 여럿 만들 수 있습니다. 모델을 공유하면서 새로 학습시키는 부분(위 LoRA 구조 그림의 오른쪽에 있는 A, B)만 쉽게 바꿔 끼울 수 있습니다.
-
레이어에 추가한 작은 matrix들만 학습시키고 효율적으로 메모리를 사용할 수 있습니다.
-
Inference 과정에서 추가적인 latency 없이 사용할 수 있습니다.
-
기존의 많은 방법들과도 동시 사용 가능합니다.
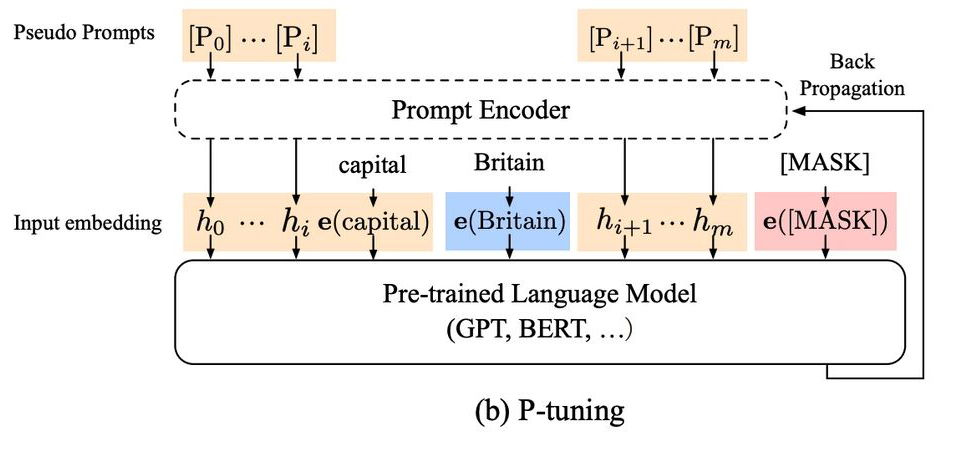
P-Tuning
-
LoRA와 기본 원리는 비슷합니다. 사전훈련된 가중치는 그대로 두고, 거기에 별도로 추가된 레이어만 새로운 데이터로 학습을 합니다.
-
임베딩 레이어에 BiLSTM과 MLP 레이어를 붙입니다. 이렇게 하면 프롬프트의 임베딩이 학습 데이터에 딱 맞게 나오도록 할 수 있습니다.
-
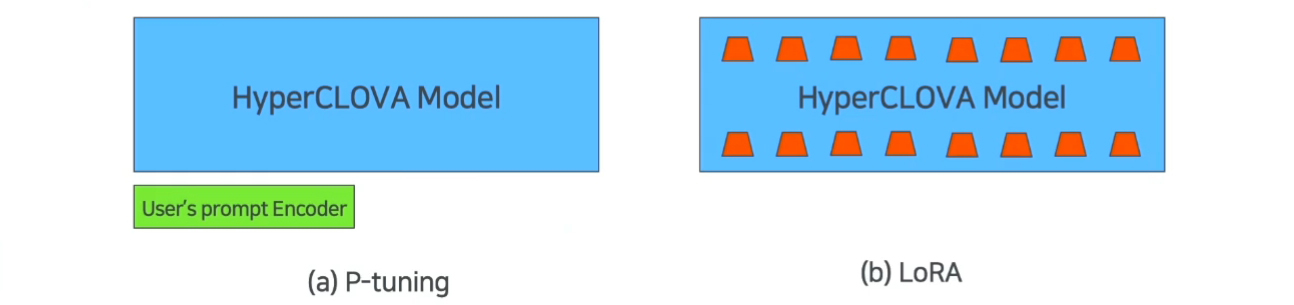
아래 그림과 같이 추가 파라미터의 위치에서 LoRA와 차이가 있습니다.
Fine-Tuning GPT Model
1. 사전훈련된 GPT 모델 선택
사전학습된 GPT 모델을 선택합니다. GPT-2, GPT-3 등 다양한 모델이 있습니다.
2. 훈련 데이터 준비
GPT 모델과 호환되는 형식의 훈련 데이터를 준비합니다. 이 과정에서는 텍스트 데이터를 토큰으로 전환하고 모델이 훈련할 수 있도록 입력-출력 쌍으로 제공합니다.
3. 파라미터 튜닝
태스크에 적절하도록 사전학습된 GPT 모델을 조정하는 작업입니다. 학습률(learning rate), 배치 크기, 에포크 수 등의 구체적인 파라미터를 정의하는 과정이 필요합니다.
4. 모델 훈련
훈련 데이터를 사용하여 모델을 훈련시킵니다. 입력-출력 쌍을 모델에 전달하고 모델의 예측 결과와 실제 출력 사이의 오류를 최소화하기 위해 모델의 파라미터를 조정합니다.
5. 모델 평가
GPT 모델의 fine-tuning이 완료된 후, 검증용 데이터를 이용하여 모델의 성능을 평가합니다. 정확도, f1 점수, BLEU 점수 등의 메트릭을 사용하여 측정할 수 있습니다.
GPT 활용 사례
일본 법률상담 서비스
2월 14일 아사히신문은 온라인 법률 상담 서비스인 ‘모두의 법률상담’을 운영하는 변호사닷컴이 'ChatGPT'를 활용한 신규 법률 상담 서비스를 제공한다고 보도했습니다. ChatGPT에 일본의 법률과 과거 판례를 학습시킨 뒤, 일반인들이 묻는 말에 답하도록 하는 방식입니다. 이 서비스는 무료 상담으로 제공될 예정이며, 보다 많은 일반인들이 쉽게 법률 상담을 받을 수 있을 것으로 보입니다.
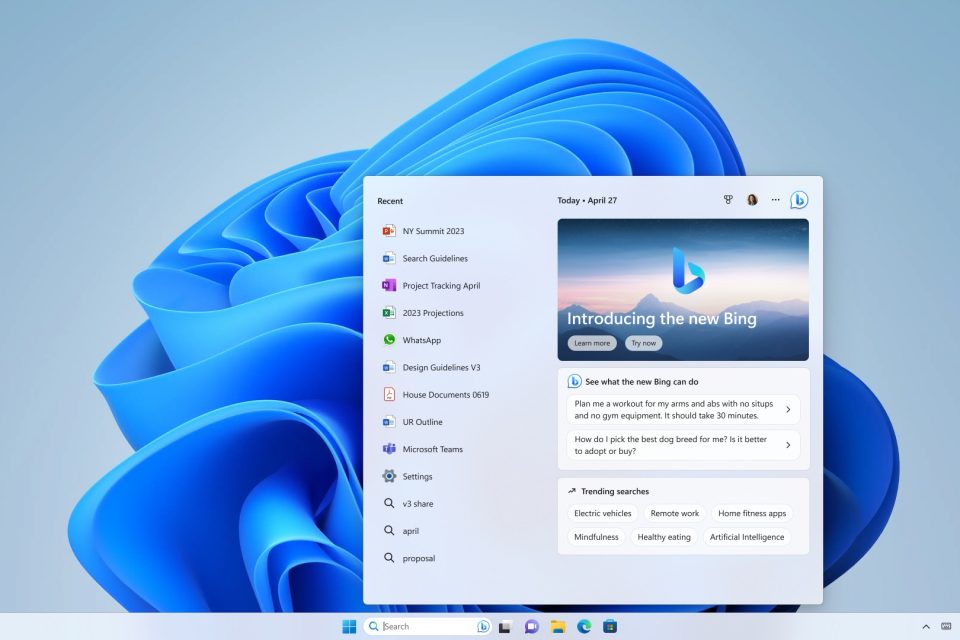
MS new ‘Bing’
마이크로소프트(MS)가 2월 28일(현지시간) 블로그를 통해 '윈도11'의 주요 업데이트 내용을 공개하면서 'ChatGPT'를 탑재한 새 검색엔진 '빙'을 결합한다고 발표했습니다. 파노스 파네이 MS 최고 제품 책임자는 "윈도 PC는 그 어느 때보다 우리 일상에 가까워졌으며, 이는 인공지능(AI) 도입이 이끄는 새로운 컴퓨팅 흐름에 따라 더욱 현실화되고 있다"면서 "새로운 AI 시대에 맞춰 발표되는 윈도11의 주요 업데이트는 사람들이 PC에서 작업하는 방식을 재창조하고 개선해 나갈 것"이라고 말했습니다. ChatGPT를 탑재한 새 검색엔진 '뉴 빙'이 구글에 빼앗긴 검색시장을 탈환할 수 있을까요?
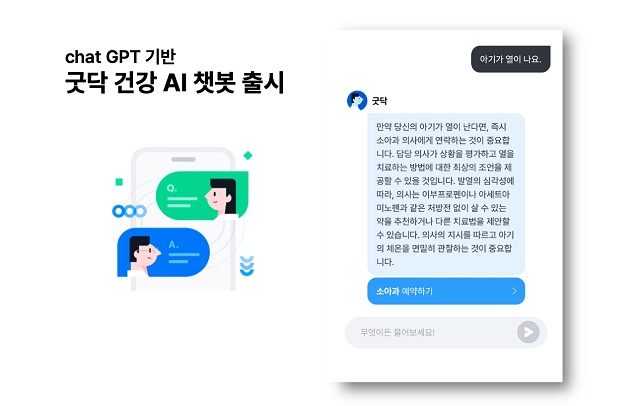
굿닥 GPT 기반 건강 AI챗봇
굿닥은 ChatGPT API가 도입된 ‘건강 AI챗봇’ 서비스를 출시했습니다. 신규 서비스는 굿닥 앱(App) 내 ‘건강AI’를 통해 사용할 수 있습니다. 건강·시술과 관련된 사용자 질문에 인공지능이 1초 이내에 답변을 제공합니다. 인공지능 답변이 즉각적으로 이루어지는 만큼, 남녀노소 누구나 쉽고 빠르게 사용이 가능하다고 합니다. AI챗봇 서비스 출시로 인공지능을 활용해 사용자 질문에 대한 직·간접적인 솔루션을 신속하게 제공할 수 있어 진료 연계성이 한층 강화될 것으로 기대됩니다.
SKT '에이닷'과 ChatGPT 연계
SK텔레콤이 성장형 AI 서비스 ‘에이닷’에 ChatGPT와 같은 생성AI(Generative AI) 모델을 접목하는 등 지속적인 R&D 투자를 통해 국내 초거대 AI 서비스 시장을 선도해나갈 방침입니다. 현재 AI 대화 서비스는 명령 위주의 ‘목적성 대화’와 친구처럼 사소한 대화를 함께 할 수 있는 ‘감성 대화’, 지식을 얻을 때 사용할 수 있는 ‘지식 대화’로 크게 나뉘어 지는데 ChatGPT와 연계되면 ChatGPT가 보유한 방대한 정보를 활용해 지식 대화가 한층 강화될 수 있을 것으로 보입니다.
ChatGPT 기술 현황
-
2023년 2월 7일 OpenAI와 파트너십을 활용하여 Microsoft는 Microsoft Bing의 프리뷰 버전 “the new Bing”을 출시했습니다.
-
중국의 검색 엔진 Baidu가 ChatGPT 스타일의 서비스 “ERNIE Bot”을 출시하겠다고 발표했습니다.
-
네이버가 2023년 상반기 중으로 ChatGPT 스타일의 서비스 “SearchGPT”을 출시하겠다고 발표했습니다.
-
러시아의 검색 엔진 Yandex가 2023년이 끝나기 전에 ChatGPT 스타일의 서비스 “YaLM 2.0”을 출시하겠다고 발표했습니다.