과학기술정보통신부와 NIA(한국지능정보사회진흥원)에서 진행한 연구 과제를 수행하였습니다. AI에 학습용(Pre-training)으로 활용될 대량의 원천 말뭉치 데이터를 구축하고, 데이터 유효성을 검증하기 위한 언어 모델(LLM)을 개발하였습니다. 언어 GPT는 챗봇 용도로 훈련된 LLM으로, 각국에 관련된 해당언어 질문에 대해 답변을 생성합니다. ChatGPT를 비롯한 언어 모델과 관련된 개념에 대한 설명은 블로그 페이지를 참고하세요.
딥로딩은 2023년 베트남어 그리고 2024년 카자흐어, 스와힐리어, 크메르어 데이터를 구축하고 AI모델을 개발하였습니다. 각국가의 언어와 문화, 가치관등을 반영한 모델입니다.
ChatGPT나 Bard와 같은 기존 거대 언어 모델들은 비영어권 데이터를 제대로 학습하지 않아 비영어권 국가의 언어어 질문에 대해 아예 답변하지 못하거나 부정확한 답변을 제공합니다. 하지만 베트남, 카자흐스탄, 캄보디아, 탄자니아 등 IT 시장은 급성장을 거듭하며 AI 서비스에 대한 수요는 커지고 있으며 각 국가는 자국 소버린(sovereign) AI모델을 보유하고자 합니다.

베트남 정부 방문 및 시연 2023.12
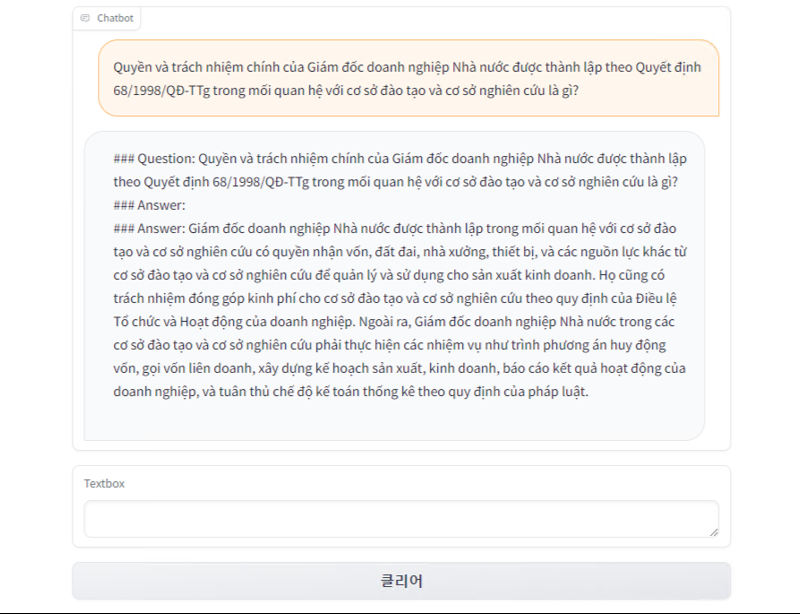
시연 화면

카자흐스탄 정부 방문 및 시연 2024.9


카자흐스탄 연수생 한국 초청 교육 2024.11
LLM모델은 각 국가의 언어로 질문을 받아 텍스트를 생성할 수 있는 소버린 언어 모델입니다.

Llama3 7B, 8B, 11B 모델을 사용하여 Instruction QA데이터를 구축하고 Fine tuning 학습을 수행하였습니다. 카자흐어와 크메르어는 사전 Pretrain 학습을 추가하여 모델의 언어능력을 먼저 향상 시켰습니다.
베트남어 말뭉치 데이터는 AI-Hub 사이트에서 다운로드 가능합니다.
AI-Hub: https://aihub.or.kr/
과학기술정보통신부와 NIA(한국지능정보사회진흥원)에서 진행한 연구 과제로 2024년 한국-베트남 IT협력프로젝트 공동협력과제로 베트남 한국파견 근로자를 위하여 비자발급, 직장생활, 한국생활 등 이해부족으로 발생 할 수 있는 다양한 어려운점을 AI로 상담하는 시범서비스를 구현하였습니다.
AI상담서비스는 챗봇 용도로 훈련된 LLM으로, 한국에 파견된 베트남 근로자를 위하여 관련된 질문에 대해 답변을 생성하는 AI서비스입니다.
근로 조건, 직장 문화, 한국 생활 등에 대한 이해 부족으로 인해 발생하는 외국인 근로자의 이직율 및 불법체류 문제는 국내 사업장의 생산성 감소 문제 뿐만 아니라 양국 인력 교류 시장의 신뢰성 저하를 초래하고 있음
AI 기반 맞춤형 직업 매칭, 다국어 지원, 실시간 상담 등을 통해 파견 전후 경험을 향상시키면서 근로 조건 정보 접근성을 개선하고, 상호 문화적 이해를 촉진함으로써 양국 인력 교류 관계 증진 기여하도록 함
- 한국과 베트남은 공동활용이 가능한 데이터셋의 시범구축을 통해 데이터 공동활용·구축 기반마련 및 양국 기업의 상호 간 발전 유도
베트남 근로자의 질문을 자연스러운 베트남어로 이해하고 의도를 해석 함
베트남 근로자에게 한국의 고용허가제 관련 정보를 질문에 맞는 내용으로 자연스러운 답변을 빠르게 생성하여 제공 함
비자 관련 최신의 정보를 업데이트 즉시 반영하여 제공 함
정보를 얻기 힘든 한국어로 되어 있는 고용허가제 관련 모든 정보를 베트남어로 얻을 수 있음
답변을 시간과 장소에 구애받지 않고 즉시 받을 수 있어 사용자의 만족도가 높음

베트남 정부 방문 서비스개발 협의 2024.10

시범서비스 화면
한국 파견 정보를 매우 쉬운 방법으로 제공하여 정보 접근이 어려운 베트남 근로자들에게 비자발급 관련 정보를 시범 서비스로 제공
한국으로 오는 유학생에 대한 안내, 국제 결혼, 베트남에서 한국 기업 취업에 대한 안내 등 다양한 한국 관련 서비스로 확장을 할 수 있음.
또한 베트남어 LLM기술로 베트남 자국의 공공 대민 서비스와 베트남 기업의 제품 상담 서비스까지 활용이 가능 함
과학기술정보통신부와 NIA(한국지능정보사회진흥원)에서 진행한 연구 과제를 수행했습니다. 일상 대화 및 특수상황에서 연령대별 은어·속어 음성 데이터 3000시간을 구축하고 데이터의 유효성을 검증하기 위한 인공지능 모델을 개발하였습니다.
다양한 연령층에서 사용하는 은어·속어 음성 데이터를 인공지능 모델을 사용하여 텍스트로 변환합니다. 이를 speech-to-text(stt)라고 하는 음성 인식(전사)이라고 합니다. 또한 인식된 은어·속어 텍스트를 표준어로 변환하여 누구나 무슨 뜻인지 이해할 수 있도록 인공지능 모델을 사용하여 자동 번역하여 제시합니다.
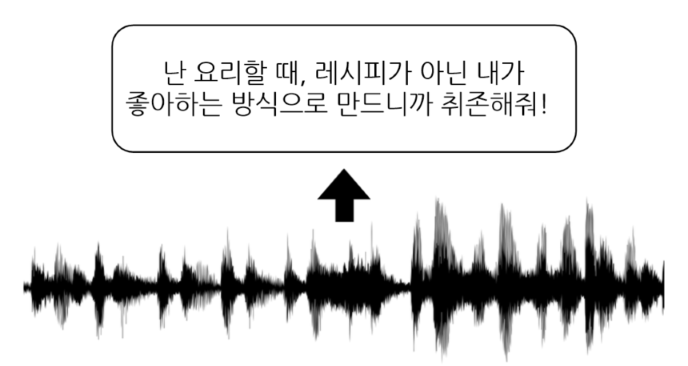
slang-stt(speech to text) 모델은 은어∙속어를 음성을 인식하여 텍스트로 변환하는 한국어 음성모델입니다. 은어와 속어가 포함되어 있는 연령대별 특징적 발화 음성 데이터를 전사하여 텍스트로 나타냅니다.
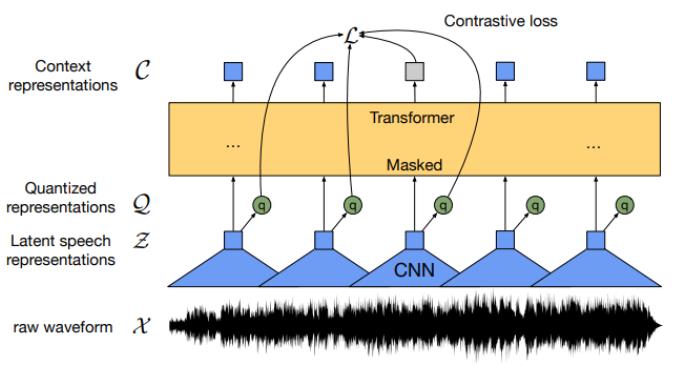
wav2vec 2.0은 2020년 페이스북에서 개발하였으며, 입력한 원시 음성데이터를 기반으로 자기지도학습을 거쳐 데이터를 보다 정확하게 인식하는 음성 모델입니다. 한국어를 포함한 51개의 언어로 pre-trained 되어 있으며, 적은 양의 데이터로도 높은 정확도를 보이는 음성 인식 모델을 구축할 수 있습니다. 기존의 VQ wav2vec보다 안정적인 아키텍처를 가졌으며, 학습된 모델을 다양한 작업에 활용할 수 있습니다. wav2vec 2.0은 일정 거리에 위치한 벡터를 예측하는 CPC(Contrastive Predictive Coding) 방법론과 일정 부분이 가려진 데이터를 트랜스포머 인코더에 입력한 후 그 부분이 무엇인지를 예측하는 mask prediction을 수행하는 MLM(Masked Language Modeling) pre-training 방법론을 사용하여 사전학습을 진행하였습니다. 사전학습 모델에 원하는 작업을 수행하도록 fine-tuning하여 모델을 구성할 수 있습니다.
연령대별 특징적 발화(은어∙속어 등) 원천 데이터
데이터는 AI-Hub 사이트에서 다운로드 가능합니다.
AI-Hub: https://aihub.or.kr/

slang-translation 모델은 은어∙속어를 표준어로 번역해주는 한국어 언어모델입니다. 은어와 속어가 포함되어 있는 연령대별 특징적 발화를 누구나 이해할 수 있는 표준어로 번역하여 나타냅니다.
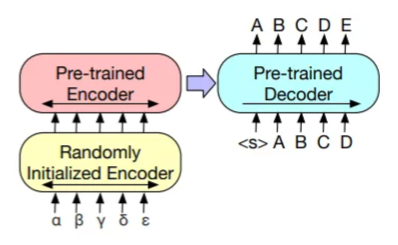
mBART(Bidirectional Auto-Regressive Transformers)는 2019년 페이스북에서 개발하였으며, 양방향 인코더와 자동 회귀 디코더를 가진 기계 번역을 목적으로 만들어진 seq2seq 모델입니다. 텍스트 이해와 생성이 모두 가능하기 때문에 번역과 요약 태스크에 적합하며, 한국어를 포함한 50여개의 언어로 pre-trained 되어 있습니다. pre-training 단계는 텍스트를 임의적인 노이즈 함수로 오염시킨 이후 기존 텍스트를 복원하기 위해 학습하는 두 가지 단계로 이루어져 있습니다.
연령대별 특징적 발화(은어∙속어 등) 라벨링 데이터
데이터는 AI-Hub 사이트에서 다운로드 가능합니다.
AI-Hub: https://aihub.or.kr/