Lorem ipsum dolor sit amet consectetur adipisicing elit. Hic aliquid quas qui minus! Dolor, ad. Odit, ullam perspiciatis nesciunt numquam explicabo, sunt ipsa libero ipsum maiores
Let's TalkLorem ipsum dolor sit amet consectetur adipisicing elit. Quos distinctio aliquam natus, mollitia eaque dolores consequuntur perspiciatis inventore sit assumenda
거대 언어 모델 GPT-3를 미세조정(fine-tuning)한 특정 전문 분야의 챗봇으로 사용자가 질문을 하면 상세하고 정확한 응답을 전달합니다.


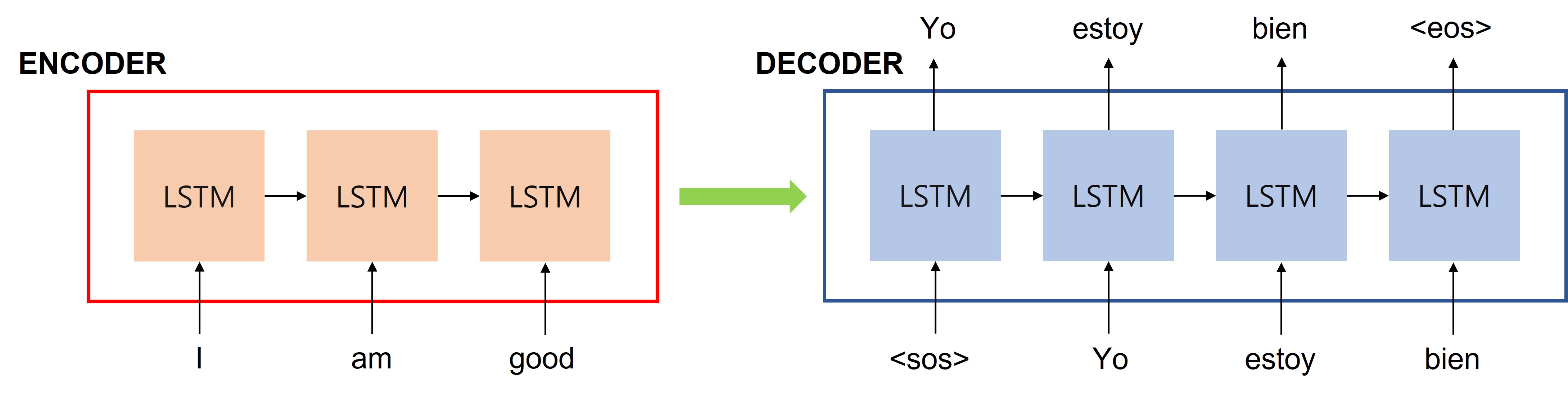
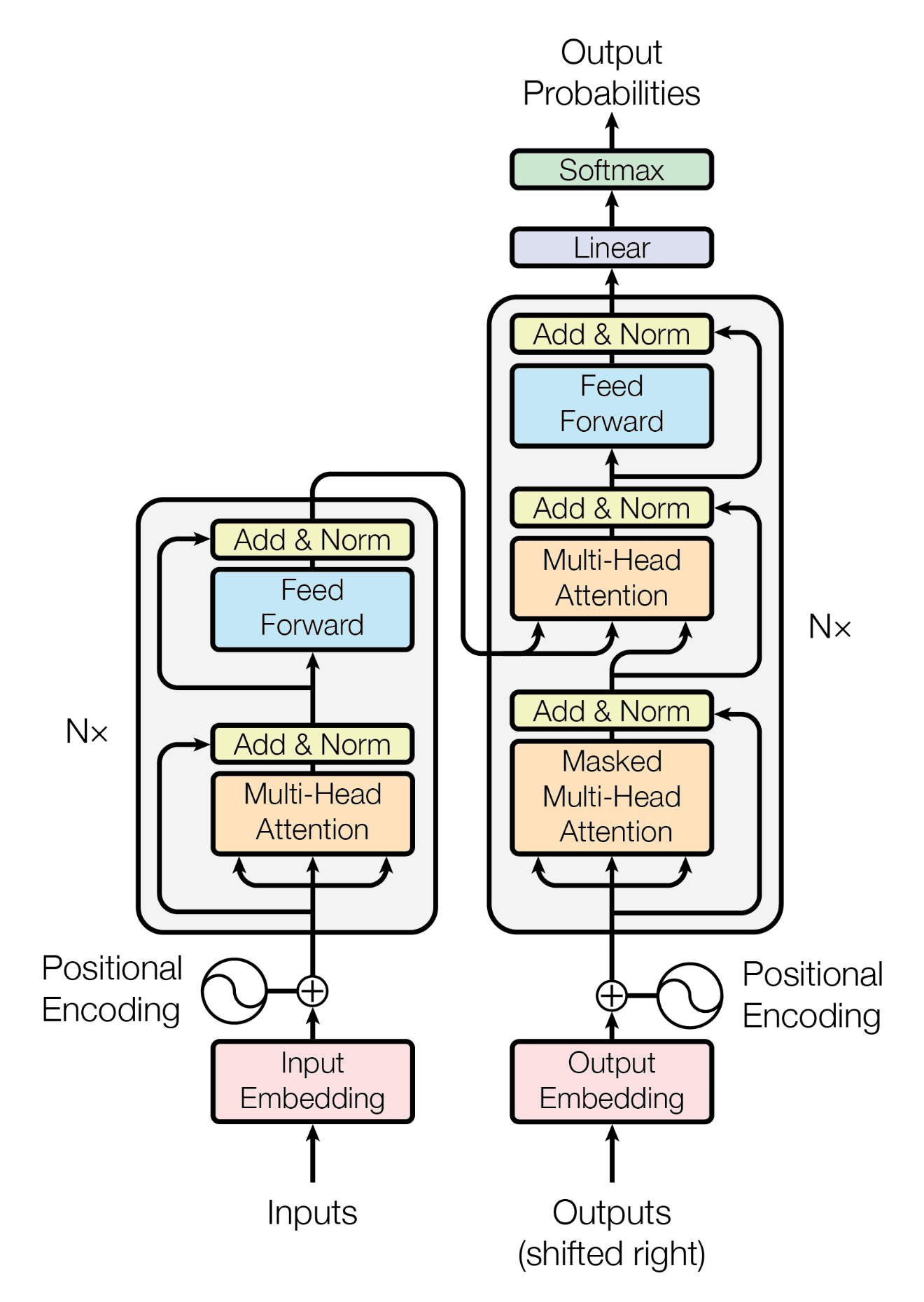
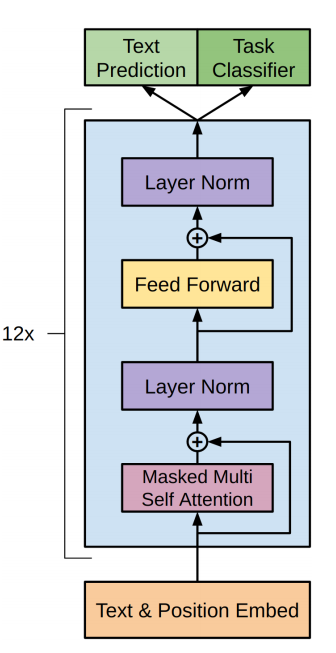
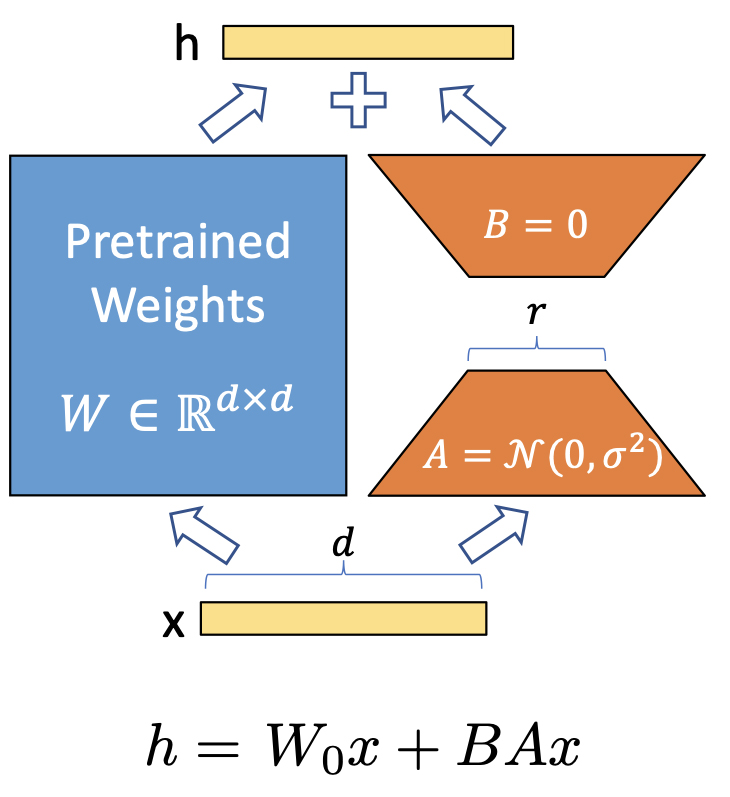
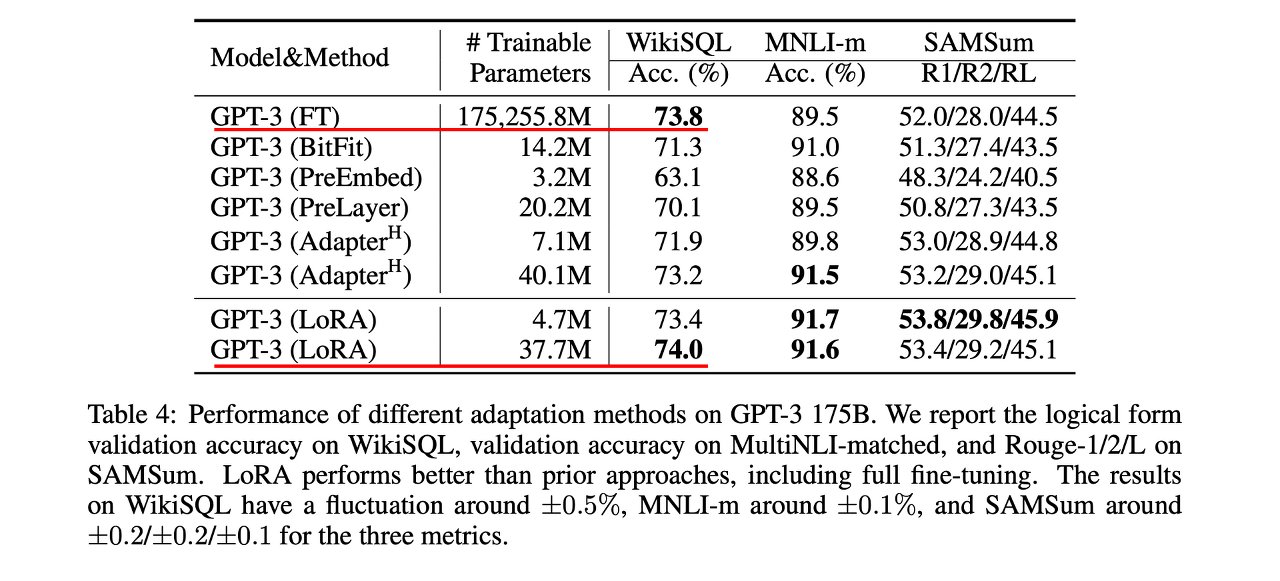
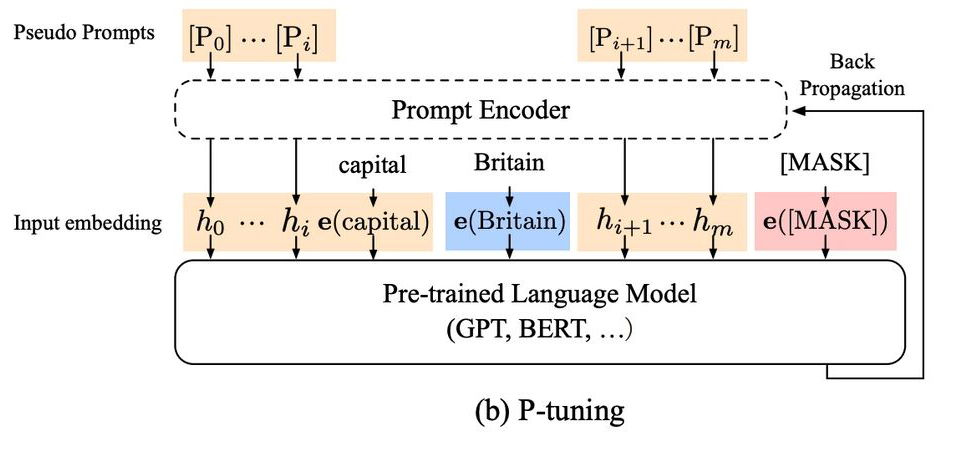
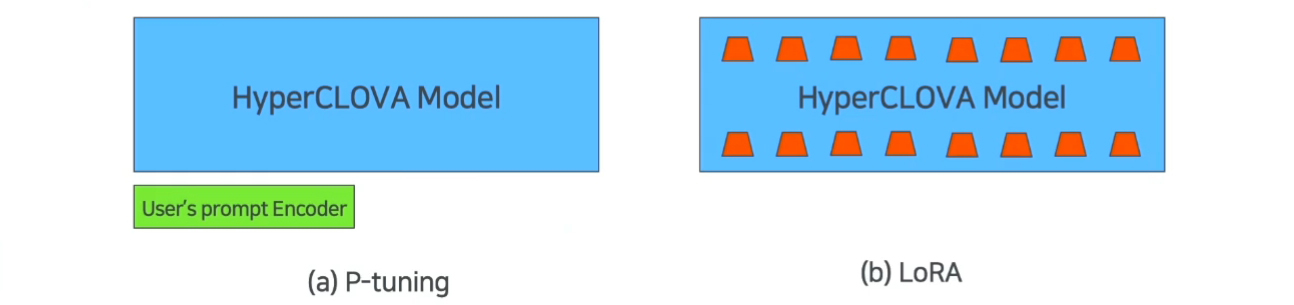
GPT 모델을 fine-tuning(미세조정)하는 방법은 대표적으로 아래와 같습니다.

가장 일반적인 접근법으로, 사전학습된 모델을 원하는 태스크에 맞도록 지도학습 데이터셋으로 학습시키는 과정을 포함합니다. 보통 수천~수만 개의 라벨링된 예시를 필요로 합니다.
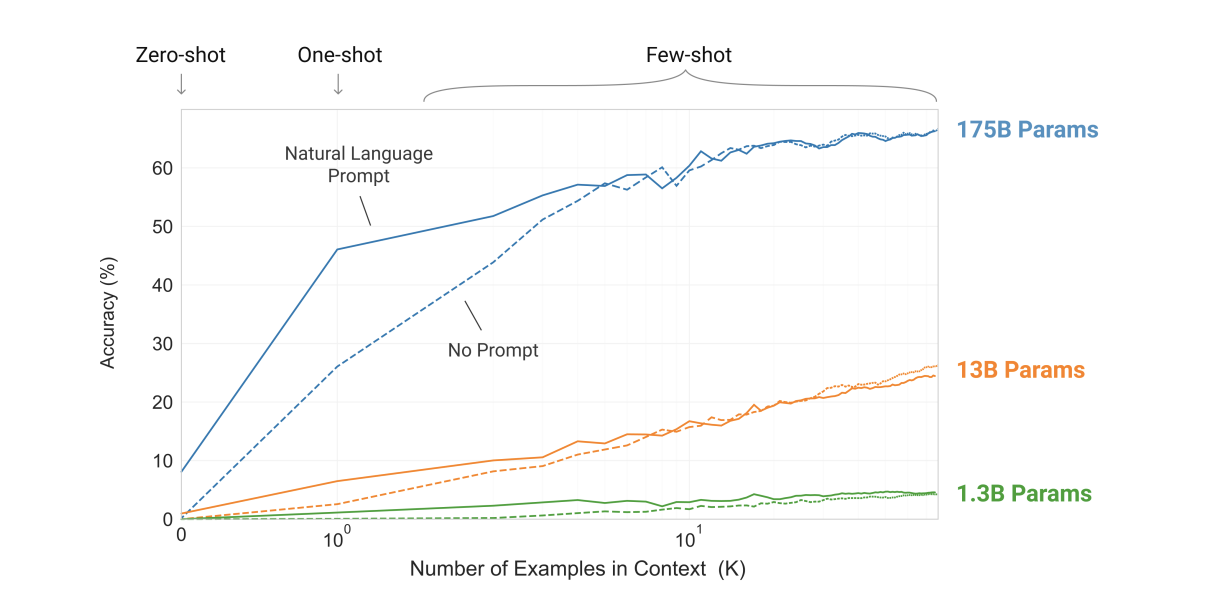
데이터셋에서 예시는 문맥과 원하는 답이 있고, few-shot은 단 K개의 문맥과 답이 주어집니다. 이후 마지막으로 단 한 개의 프롬프트가 주어지면, 모델은 정확한 답을 생성해 내야 합니다. 모델의 context window에 넣을 수 있는 만큼 많은 예시(K)를 넣습니다. 일반적으로 가능한 context 길이 2048에 들어가는 10~100개의 예시를 넣습니다.
few-shot과 비슷하나 단 한 개의 예시와, 태스크에 대한 자연어 지시문(instruction)이 제공된다는 점이 다릅니다.
예시는 넣지 않고, 수행할 태스크에 대한 설명(description) 혹은 지시문(instruction)만을 넣습니다. 사람이 태스크를 수행하는 것과 가장 가까운 방식입니다. 사람은 텍스트 지시문(예: 'Cheese'라는 영어 단어를 프랑스어로 번역하라)만을 보고도 무엇을 해야 할지 알 수 있기 때문입니다.
모델 선택
데이터 준비
파라미터 튜닝
모델 훈련
모델 평가
1. 사전훈련된 GPT 모델 선택
사전학습된 GPT 모델을 선택합니다. GPT-2, GPT-3 등 다양한 모델이 있습니다.
2. 훈련 데이터 준비
GPT 모델과 호환되는 형식의 훈련 데이터를 준비합니다. 이 과정에서는 텍스트 데이터를 토큰으로 전환하고 모델이 훈련할 수 있도록 입력-출력 쌍으로 제공합니다.
3. 파라미터 튜닝
태스크에 적절하도록 사전학습된 GPT 모델을 조정하는 작업입니다. 학습률(learning rate), 배치 크기, 에포크 수 등의 구체적인 파라미터를 정의하는 과정이 필요합니다.
4. 모델 훈련
훈련 데이터를 사용하여 모델을 훈련시킵니다. 입력-출력 쌍을 모델에 전달하고 모델의 예측 결과와 실제 출력 사이의 오류를 최소화하기 위해 모델의 파라미터를 조정합니다.
5. 모델 평가
GPT 모델의 fine-tuning이 완료된 후, 검증용 데이터를 이용하여 모델의 성능을 평가합니다. 정확도, f1 점수, BLEU 점수 등의 메트릭을 사용하여 측정할 수 있습니다.

2월 14일 아사히신문은 온라인 법률 상담 서비스인 ‘모두의 법률상담’을 운영하는 변호사닷컴이 'ChatGPT'를 활용한 신규 법률 상담 서비스를 제공한다고 보도했습니다. ChatGPT에 일본의 법률과 과거 판례를 학습시킨 뒤, 일반인들이 묻는 말에 답하도록 하는 방식입니다. 이 서비스는 무료 상담으로 제공될 예정이며, 보다 많은 일반인들이 쉽게 법률 상담을 받을 수 있을 것으로 보입니다.
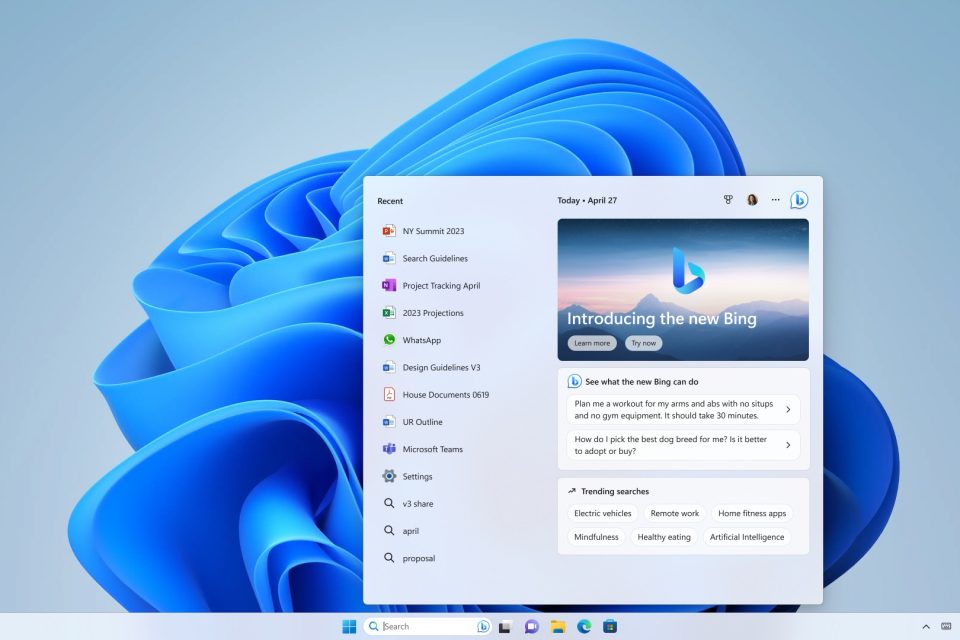
마이크로소프트(MS)가 2월 28일(현지시간) 블로그를 통해 '윈도11'의 주요 업데이트 내용을 공개하면서 'ChatGPT'를 탑재한 새 검색엔진 '빙'을 결합한다고 발표했습니다. 파노스 파네이 MS 최고 제품 책임자는 "윈도 PC는 그 어느 때보다 우리 일상에 가까워졌으며, 이는 인공지능(AI) 도입이 이끄는 새로운 컴퓨팅 흐름에 따라 더욱 현실화되고 있다"면서 "새로운 AI 시대에 맞춰 발표되는 윈도11의 주요 업데이트는 사람들이 PC에서 작업하는 방식을 재창조하고 개선해 나갈 것"이라고 말했습니다. ChatGPT를 탑재한 새 검색엔진 '뉴 빙'이 구글에 빼앗긴 검색시장을 탈환할 수 있을까요?
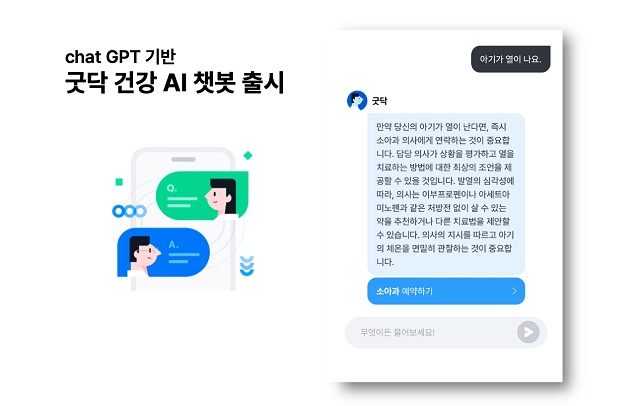
굿닥은 ChatGPT API가 도입된 ‘건강 AI챗봇’ 서비스를 출시했습니다. 신규 서비스는 굿닥 앱(App) 내 ‘건강AI’를 통해 사용할 수 있습니다. 건강·시술과 관련된 사용자 질문에 인공지능이 1초 이내에 답변을 제공합니다. 인공지능 답변이 즉각적으로 이루어지는 만큼, 남녀노소 누구나 쉽고 빠르게 사용이 가능하다고 합니다. AI챗봇 서비스 출시로 인공지능을 활용해 사용자 질문에 대한 직·간접적인 솔루션을 신속하게 제공할 수 있어 진료 연계성이 한층 강화될 것으로 기대됩니다.

SK텔레콤이 성장형 AI 서비스 ‘에이닷’에 ChatGPT와 같은 생성AI(Generative AI) 모델을 접목하는 등 지속적인 R&D 투자를 통해 국내 초거대 AI 서비스 시장을 선도해나갈 방침입니다. 현재 AI 대화 서비스는 명령 위주의 ‘목적성 대화’와 친구처럼 사소한 대화를 함께 할 수 있는 ‘감성 대화’, 지식을 얻을 때 사용할 수 있는 ‘지식 대화’로 크게 나뉘어 지는데 ChatGPT와 연계되면 ChatGPT가 보유한 방대한 정보를 활용해 지식 대화가 한층 강화될 수 있을 것으로 보입니다.
상호: 주식회사 딥로딩 | 주소지: 서울특별시 강남구 도곡로 123, 대경빌딩 2층 | 사업자등록번호: 776-81-02502 | 이메일: smoh@deeploading.com
© Copyrights 2023 DeepLoading co,.ltd. all rights reserved.