Lorem ipsum dolor sit amet consectetur adipisicing elit. Hic aliquid quas qui minus! Dolor, ad. Odit, ullam perspiciatis nesciunt numquam explicabo, sunt ipsa libero ipsum maiores
Let's TalkLorem ipsum dolor sit amet consectetur adipisicing elit. Quos distinctio aliquam natus, mollitia eaque dolores consequuntur perspiciatis inventore sit assumenda
과학기술정보통신부와 NIA(한국지능정보사회진흥원)에서 진행한 연구 과제를 수행했습니다. 일상 대화 및 특수상황에서 연령대별 은어·속어 음성 데이터 3000시간을 구축하고 데이터의 유효성을 검증하기 위한 인공지능 모델을 개발하였습니다.
다양한 연령층에서 사용하는 은어·속어 음성 데이터를 인공지능 모델을 사용하여 텍스트로 변환합니다. 이를 speech-to-text(stt)라고 하는 음성 인식(전사)이라고 합니다. 또한 인식된 은어·속어 텍스트를 표준어로 변환하여 누구나 무슨 뜻인지 이해할 수 있도록 인공지능 모델을 사용하여 자동 번역하여 제시합니다.
slang-stt(speech to text) 모델은 은어∙속어를 음성을 인식하여 텍스트로 변환하는 한국어 음성모델입니다. 은어와 속어가 포함되어 있는 연령대별 특징적 발화 음성 데이터를 전사하여 텍스트로 나타냅니다.
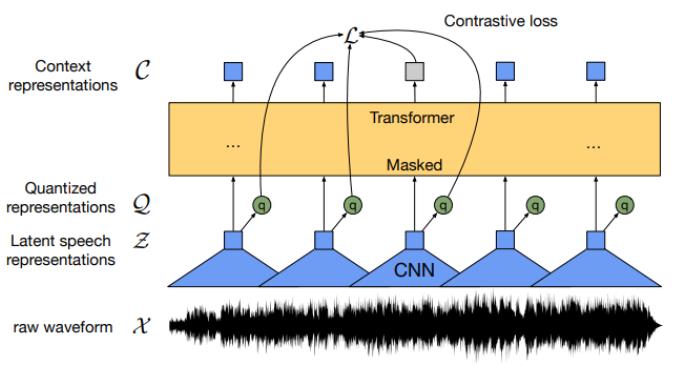
wav2vec 2.0은 2020년 페이스북에서 개발하였으며, 입력한 원시 음성데이터를 기반으로 자기지도학습을 거쳐 데이터를 보다 정확하게 인식하는 음성 모델입니다. 한국어를 포함한 51개의 언어로 pre-trained 되어 있으며, 적은 양의 데이터로도 높은 정확도를 보이는 음성 인식 모델을 구축할 수 있습니다. 기존의 VQ wav2vec보다 안정적인 아키텍처를 가졌으며, 학습된 모델을 다양한 작업에 활용할 수 있습니다. wav2vec 2.0은 일정 거리에 위치한 벡터를 예측하는 CPC(Contrastive Predictive Coding) 방법론과 일정 부분이 가려진 데이터를 트랜스포머 인코더에 입력한 후 그 부분이 무엇인지를 예측하는 mask prediction을 수행하는 MLM(Masked Language Modeling) pre-training 방법론을 사용하여 사전학습을 진행하였습니다. 사전학습 모델에 원하는 작업을 수행하도록 fine-tuning하여 모델을 구성할 수 있습니다.
연령대별 특징적 발화(은어∙속어 등) 원천 데이터
데이터는 AI-Hub 사이트에서 다운로드 가능합니다.
AI-Hub: https://aihub.or.kr/

slang-translation 모델은 은어∙속어를 표준어로 번역해주는 한국어 언어모델입니다. 은어와 속어가 포함되어 있는 연령대별 특징적 발화를 누구나 이해할 수 있는 표준어로 번역하여 나타냅니다.
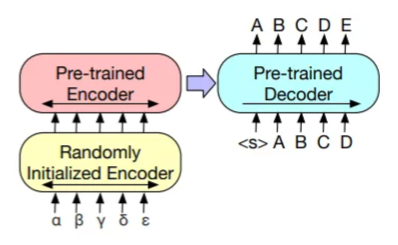
mBART(Bidirectional Auto-Regressive Transformers)는 2019년 페이스북에서 개발하였으며, 양방향 인코더와 자동 회귀 디코더를 가진 기계 번역을 목적으로 만들어진 seq2seq 모델입니다. 텍스트 이해와 생성이 모두 가능하기 때문에 번역과 요약 태스크에 적합하며, 한국어를 포함한 50여개의 언어로 pre-trained 되어 있습니다. pre-training 단계는 텍스트를 임의적인 노이즈 함수로 오염시킨 이후 기존 텍스트를 복원하기 위해 학습하는 두 가지 단계로 이루어져 있습니다.
연령대별 특징적 발화(은어∙속어 등) 라벨링 데이터
데이터는 AI-Hub 사이트에서 다운로드 가능합니다.
AI-Hub: https://aihub.or.kr/